API - Data Pre-Processing¶
|
Create an affine transform matrix for image rotation. |
|
Create an affine transformation matrix for image horizontal flipping. |
|
Create an affine transformation for image vertical flipping. |
|
Create an affine transform matrix for image shifting. |
|
Create affine transform matrix for image shearing. |
|
Create an affine transform matrix for zooming/scaling an image’s height and width. |
|
Get affine transform matrix for zooming/scaling that height and width are changed independently. |
|
Convert the matrix from Cartesian coordinates (the origin in the middle of image) to Image coordinates (the origin on the top-left of image). |
|
Return transformed images by given an affine matrix in Scipy format (x is height). |
|
Return transformed images by given an affine matrix in OpenCV format (x is width). |
|
Transform keypoint coordinates according to a given affine transform matrix. |
|
Projective transform by given coordinates, usually 4 coordinates. |
|
Rotate an image randomly or non-randomly. |
|
Rotate multiple images with the same arguments, randomly or non-randomly. |
|
Randomly or centrally crop an image. |
|
Randomly or centrally crop multiple images. |
|
Flip the axis of an image, such as flip left and right, up and down, randomly or non-randomly, |
|
Flip the axises of multiple images together, such as flip left and right, up and down, randomly or non-randomly, |
|
Shift an image randomly or non-randomly. |
|
Shift images with the same arguments, randomly or non-randomly. |
|
Shear an image randomly or non-randomly. |
|
Shear images with the same arguments, randomly or non-randomly. |
|
Shear an image randomly or non-randomly. |
|
Shear images with the same arguments, randomly or non-randomly. |
|
Swirl an image randomly or non-randomly, see scikit-image swirl API and example. |
|
Swirl multiple images with the same arguments, randomly or non-randomly. |
|
Elastic transformation for image as described in [Simard2003]. |
|
Elastic transformation for images as described in [Simard2003]. |
|
Zooming/Scaling a single image that height and width are changed together. |
|
Zooming/Scaling a single image that height and width are changed independently. |
|
Zoom in and out of images with the same arguments, randomly or non-randomly. |
|
Change the brightness of a single image, randomly or non-randomly. |
|
Change the brightness of multiply images, randomly or non-randomly. |
|
Perform illumination augmentation for a single image, randomly or non-randomly. |
|
Input RGB image [0~255] return HSV image [0~1]. |
|
Input HSV image [0~1] return RGB image [0~255]. |
|
Adjust hue of an RGB image. |
|
Resize an image by given output size and method. |
|
Scales each value in the pixels of the image. |
|
Normalize an image by rescale, samplewise centering and samplewise centering in order. |
|
Normalize every pixels by the same given mean and std, which are usually compute from all examples. |
|
Shift the channels of an image, randomly or non-randomly, see numpy.rollaxis. |
|
Shift the channels of images with the same arguments, randomly or non-randomly, see numpy.rollaxis. |
|
Randomly set some pixels to zero by a given keeping probability. |
|
Converts a numpy array to PIL image object (uint8 format). |
|
Find iso-valued contours in a 2D array for a given level value, returns list of (n, 2)-ndarrays see skimage.measure.find_contours. |
|
Inputs a list of points, return a 2D image. |
|
Return fast binary morphological dilation of an image. |
|
Return greyscale morphological dilation of an image, see skimage.morphology.dilation. |
|
Return binary morphological erosion of an image, see skimage.morphology.binary_erosion. |
|
Return greyscale morphological erosion of an image, see skimage.morphology.erosion. |
|
Scale down one coordinates from pixel unit to the ratio of image size i.e. |
|
Scale down a list of coordinates from pixel unit to the ratio of image size i.e. |
|
Convert one coordinate [x, y, w (or x2), h (or y2)] in ratio format to image coordinate format. |
Convert one coordinate [x_center, y_center, w, h] to [x1, y1, x2, y2] in up-left and botton-right format. |
|
Convert one coordinate [x1, y1, x2, y2] to [x_center, y_center, w, h]. |
|
Convert one coordinate [x_center, y_center, w, h] to [x, y, w, h]. |
|
Convert one coordinate [x, y, w, h] to [x_center, y_center, w, h]. |
|
|
Input string format of class, x, y, w, h, return list of list format. |
|
Parse darknet annotation format into two lists for class and bounding box. |
|
Left-right flip the image and coordinates for object detection. |
|
Resize an image, and compute the new bounding box coordinates. |
|
Randomly or centrally crop an image, and compute the new bounding box coordinates. |
|
Shift an image randomly or non-randomly, and compute the new bounding box coordinates. |
|
Zoom in and out of a single image, randomly or non-randomly, and compute the new bounding box coordinates. |
|
Randomly crop an image and corresponding keypoints without influence scales, given by |
|
Reszie the image to make either its width or height equals to the given sizes. |
|
Rotate an image and corresponding keypoints. |
|
Flip an image and corresponding keypoints. |
|
Randomly resize an image and corresponding keypoints. |
|
Randomly resize an image and corresponding keypoints based on shorter edgeself. |
|
Pads each sequence to the same length: the length of the longest sequence. |
|
Remove padding. |
|
Set all tokens(ids) after END token to the padding value, and then shorten (option) it to the maximum sequence length in this batch. |
|
Add special start token(id) in the beginning of each sequence. |
|
Add special end token(id) in the end of each sequence. |
|
Add special end token(id) in the end of each sequence. |
|
Return mask for sequences. |
Affine Transform¶
Python can be FAST¶
Image augmentation is a critical step in deep learning.
Though TensorFlow has provided tf.image,
image augmentation often remains as a key bottleneck.
tf.image has three limitations:
Real-world visual tasks such as object detection, segmentation, and pose estimation must cope with image meta-data (e.g., coordinates). These data are beyond
tf.imagewhich processes images as tensors.tf.imageoperators breaks the pure Python programing experience (i.e., users have to usetf.py_funcin order to call image functions written in Python); however, frequent uses oftf.py_funcslow down TensorFlow, making users hard to balance flexibility and performance.tf.imageAPI is inflexible. Image operations are performed in an order. They are hard to jointly optimize. More importantly, sequential image operations can significantly reduces the quality of images, thus affecting training accuracy.
TensorLayer addresses these limitations by providing a
high-performance image augmentation API in Python.
This API bases on affine transformation and cv2.wrapAffine.
It allows you to combine multiple image processing functions into
a single matrix operation. This combined operation
is executed by the fast cv2 library, offering 78x performance improvement (observed in
openpose-plus for example).
The following example illustrates the rationale
behind this tremendous speed up.
Example¶
The source code of complete examples can be found here. The following is a typical Python program that applies rotation, shifting, flipping, zooming and shearing to an image,
image = tl.vis.read_image('tiger.jpeg')
xx = tl.prepro.rotation(image, rg=-20, is_random=False)
xx = tl.prepro.flip_axis(xx, axis=1, is_random=False)
xx = tl.prepro.shear2(xx, shear=(0., -0.2), is_random=False)
xx = tl.prepro.zoom(xx, zoom_range=0.8)
xx = tl.prepro.shift(xx, wrg=-0.1, hrg=0, is_random=False)
tl.vis.save_image(xx, '_result_slow.png')
However, by leveraging affine transformation, image operations can be combined into one:
# 1. Create required affine transformation matrices
M_rotate = tl.prepro.affine_rotation_matrix(angle=20)
M_flip = tl.prepro.affine_horizontal_flip_matrix(prob=1)
M_shift = tl.prepro.affine_shift_matrix(wrg=0.1, hrg=0, h=h, w=w)
M_shear = tl.prepro.affine_shear_matrix(x_shear=0.2, y_shear=0)
M_zoom = tl.prepro.affine_zoom_matrix(zoom_range=0.8)
# 2. Combine matrices
# NOTE: operations are applied in a reversed order (i.e., rotation is performed first)
M_combined = M_shift.dot(M_zoom).dot(M_shear).dot(M_flip).dot(M_rotate)
# 3. Convert the matrix from Cartesian coordinates (the origin in the middle of image)
# to image coordinates (the origin on the top-left of image)
transform_matrix = tl.prepro.transform_matrix_offset_center(M_combined, x=w, y=h)
# 4. Transform the image using a single operation
result = tl.prepro.affine_transform_cv2(image, transform_matrix) # 76 times faster
tl.vis.save_image(result, '_result_fast.png')
The following figure illustrates the rational behind combined affine transformation.
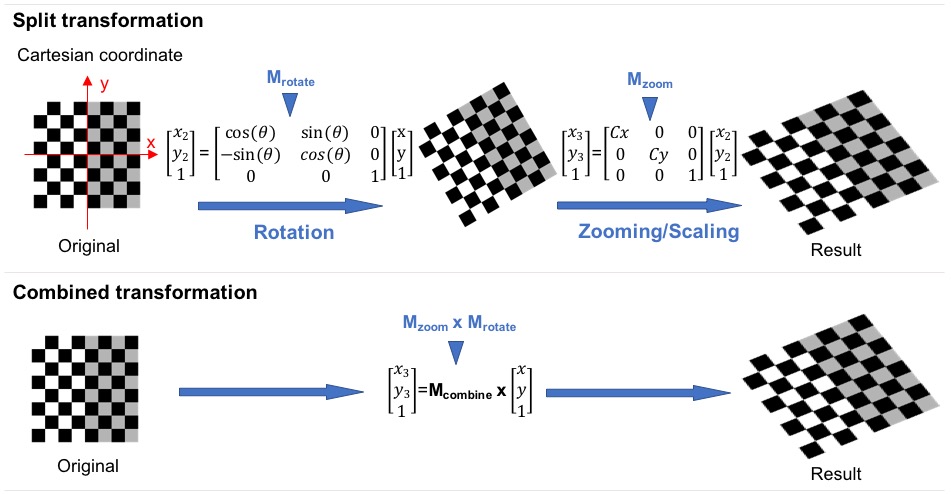
Using combined affine transformation has two key benefits. First, it allows you to leverage a pure Python API to achieve orders of magnitudes of speed up in image augmentation, and thus prevent data pre-processing from becoming a bottleneck in training. Second, performing sequential image transformation requires multiple image interpolations. This produces low-quality input images. In contrast, a combined transformation performs the interpolation only once, and thus preserve the content in an image. The following figure illustrates these two benefits:

The major reason for combined affine transformation being fast is because it has lower computational complexity.
Assume we have k affine transformations T1, ..., Tk, where Ti can be represented by 3x3 matrixes.
The sequential transformation can be represented as y = Tk (... T1(x)),
and the time complexity is O(k N) where N is the cost of applying one transformation to image x.
N is linear to the size of x.
For the combined transformation y = (Tk ... T1) (x)
the time complexity is O(27(k - 1) + N) = max{O(27k), O(N)} = O(N) (assuming 27k << N) where 27 = 3^3 is the cost for combining two transformations.
Get rotation matrix¶
-
tensorlayer.prepro.affine_rotation_matrix(angle=(-20, 20))[source]¶ Create an affine transform matrix for image rotation. NOTE: In OpenCV, x is width and y is height.
- Parameters
angle (int/float or tuple of two int/float) –
- Degree to rotate, usually -180 ~ 180.
int/float, a fixed angle.
tuple of 2 floats/ints, randomly sample a value as the angle between these 2 values.
- Returns
An affine transform matrix.
- Return type
numpy.array
Get horizontal flipping matrix¶
-
tensorlayer.prepro.affine_horizontal_flip_matrix(prob=0.5)[source]¶ Create an affine transformation matrix for image horizontal flipping. NOTE: In OpenCV, x is width and y is height.
- Parameters
prob (float) – Probability to flip the image. 1.0 means always flip.
- Returns
An affine transform matrix.
- Return type
numpy.array
Get vertical flipping matrix¶
-
tensorlayer.prepro.affine_vertical_flip_matrix(prob=0.5)[source]¶ Create an affine transformation for image vertical flipping. NOTE: In OpenCV, x is width and y is height.
- Parameters
prob (float) – Probability to flip the image. 1.0 means always flip.
- Returns
An affine transform matrix.
- Return type
numpy.array
Get shifting matrix¶
-
tensorlayer.prepro.affine_shift_matrix(wrg=(-0.1, 0.1), hrg=(-0.1, 0.1), w=200, h=200)[source]¶ Create an affine transform matrix for image shifting. NOTE: In OpenCV, x is width and y is height.
- Parameters
wrg (float or tuple of floats) –
- Range to shift on width axis, -1 ~ 1.
float, a fixed distance.
tuple of 2 floats, randomly sample a value as the distance between these 2 values.
hrg (float or tuple of floats) –
- Range to shift on height axis, -1 ~ 1.
float, a fixed distance.
tuple of 2 floats, randomly sample a value as the distance between these 2 values.
h (w,) – The width and height of the image.
- Returns
An affine transform matrix.
- Return type
numpy.array
Get shearing matrix¶
-
tensorlayer.prepro.affine_shear_matrix(x_shear=(-0.1, 0.1), y_shear=(-0.1, 0.1))[source]¶ Create affine transform matrix for image shearing. NOTE: In OpenCV, x is width and y is height.
- Parameters
shear (tuple of two floats) – Percentage of shears for width and height directions.
- Returns
An affine transform matrix.
- Return type
numpy.array
Get zooming matrix¶
-
tensorlayer.prepro.affine_zoom_matrix(zoom_range=(0.8, 1.1))[source]¶ Create an affine transform matrix for zooming/scaling an image’s height and width. OpenCV format, x is width.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
zoom_range (float or tuple of 2 floats) –
- The zooming/scaling ratio, greater than 1 means larger.
float, a fixed ratio.
tuple of 2 floats, randomly sample a value as the ratio between these 2 values.
- Returns
An affine transform matrix.
- Return type
numpy.array
Get respective zooming matrix¶
-
tensorlayer.prepro.affine_respective_zoom_matrix(w_range=0.8, h_range=1.1)[source]¶ Get affine transform matrix for zooming/scaling that height and width are changed independently. OpenCV format, x is width.
- Parameters
w_range (float or tuple of 2 floats) –
- The zooming/scaling ratio of width, greater than 1 means larger.
float, a fixed ratio.
tuple of 2 floats, randomly sample a value as the ratio between 2 values.
h_range (float or tuple of 2 floats) –
- The zooming/scaling ratio of height, greater than 1 means larger.
float, a fixed ratio.
tuple of 2 floats, randomly sample a value as the ratio between 2 values.
- Returns
An affine transform matrix.
- Return type
numpy.array
Cartesian to image coordinates¶
-
tensorlayer.prepro.transform_matrix_offset_center(matrix, y, x)[source]¶ Convert the matrix from Cartesian coordinates (the origin in the middle of image) to Image coordinates (the origin on the top-left of image).
- Parameters
matrix (numpy.array) – Transform matrix.
and y (x) – Size of image.
- Returns
The transform matrix.
- Return type
numpy.array
Examples
See
tl.prepro.rotation,tl.prepro.shear,tl.prepro.zoom.
Apply image transform¶
-
tensorlayer.prepro.affine_transform_cv2(x, transform_matrix, flags=None, border_mode='constant')[source]¶ Return transformed images by given an affine matrix in OpenCV format (x is width). (Powered by OpenCV2, faster than
tl.prepro.affine_transform)- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
transform_matrix (numpy.array) – A transform matrix, OpenCV format.
border_mode (str) –
constant, pad the image with a constant value (i.e. black or 0)
replicate, the row or column at the very edge of the original is replicated to the extra border.
Examples
>>> M_shear = tl.prepro.affine_shear_matrix(intensity=0.2, is_random=False) >>> M_zoom = tl.prepro.affine_zoom_matrix(zoom_range=0.8) >>> M_combined = M_shear.dot(M_zoom) >>> result = tl.prepro.affine_transform_cv2(image, M_combined)
Apply keypoint transform¶
-
tensorlayer.prepro.affine_transform_keypoints(coords_list, transform_matrix)[source]¶ Transform keypoint coordinates according to a given affine transform matrix. OpenCV format, x is width.
Note that, for pose estimation task, flipping requires maintaining the left and right body information. We should not flip the left and right body, so please use
tl.prepro.keypoint_random_flip.- Parameters
coords_list (list of list of tuple/list) – The coordinates e.g., the keypoint coordinates of every person in an image.
transform_matrix (numpy.array) – Transform matrix, OpenCV format.
Examples
>>> # 1. get all affine transform matrices >>> M_rotate = tl.prepro.affine_rotation_matrix(angle=20) >>> M_flip = tl.prepro.affine_horizontal_flip_matrix(prob=1) >>> # 2. combine all affine transform matrices to one matrix >>> M_combined = dot(M_flip).dot(M_rotate) >>> # 3. transfrom the matrix from Cartesian coordinate (the origin in the middle of image) >>> # to Image coordinate (the origin on the top-left of image) >>> transform_matrix = tl.prepro.transform_matrix_offset_center(M_combined, x=w, y=h) >>> # 4. then we can transfrom the image once for all transformations >>> result = tl.prepro.affine_transform_cv2(image, transform_matrix) # 76 times faster >>> # 5. transform keypoint coordinates >>> coords = [[(50, 100), (100, 100), (100, 50), (200, 200)], [(250, 50), (200, 50), (200, 100)]] >>> coords_result = tl.prepro.affine_transform_keypoints(coords, transform_matrix)
Images¶
Projective transform by points¶
-
tensorlayer.prepro.projective_transform_by_points(x, src, dst, map_args=None, output_shape=None, order=1, mode='constant', cval=0.0, clip=True, preserve_range=False)[source]¶ Projective transform by given coordinates, usually 4 coordinates.
see scikit-image.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
src (list or numpy) – The original coordinates, usually 4 coordinates of (width, height).
dst (list or numpy) – The coordinates after transformation, the number of coordinates is the same with src.
map_args (dictionary or None) – Keyword arguments passed to inverse map.
output_shape (tuple of 2 int) – Shape of the output image generated. By default the shape of the input image is preserved. Note that, even for multi-band images, only rows and columns need to be specified.
order (int) –
- The order of interpolation. The order has to be in the range 0-5:
0 Nearest-neighbor
1 Bi-linear (default)
2 Bi-quadratic
3 Bi-cubic
4 Bi-quartic
5 Bi-quintic
mode (str) – One of constant (default), edge, symmetric, reflect or wrap. Points outside the boundaries of the input are filled according to the given mode. Modes match the behaviour of numpy.pad.
cval (float) – Used in conjunction with mode constant, the value outside the image boundaries.
clip (boolean) – Whether to clip the output to the range of values of the input image. This is enabled by default, since higher order interpolation may produce values outside the given input range.
preserve_range (boolean) – Whether to keep the original range of values. Otherwise, the input image is converted according to the conventions of img_as_float.
- Returns
A processed image.
- Return type
numpy.array
Examples
Assume X is an image from CIFAR-10, i.e. shape == (32, 32, 3)
>>> src = [[0,0],[0,32],[32,0],[32,32]] # [w, h] >>> dst = [[10,10],[0,32],[32,0],[32,32]] >>> x = tl.prepro.projective_transform_by_points(X, src, dst)
References
Rotation¶
-
tensorlayer.prepro.rotation(x, rg=20, is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Rotate an image randomly or non-randomly.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
rg (int or float) – Degree to rotate, usually 0 ~ 180.
is_random (boolean) – If True, randomly rotate. Default is False
col_index and channel_index (row_index) – Index of row, col and channel, default (0, 1, 2), for theano (1, 2, 0).
fill_mode (str) – Method to fill missing pixel, default nearest, more options constant, reflect or wrap, see scipy ndimage affine_transform
cval (float) – Value used for points outside the boundaries of the input if mode=`constant`. Default is 0.0
order (int) – The order of interpolation. The order has to be in the range 0-5. See
tl.prepro.affine_transformand scipy ndimage affine_transform
- Returns
A processed image.
- Return type
numpy.array
Examples
>>> x --> [row, col, 1] >>> x = tl.prepro.rotation(x, rg=40, is_random=False) >>> tl.vis.save_image(x, 'im.png')
-
tensorlayer.prepro.rotation_multi(x, rg=20, is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Rotate multiple images with the same arguments, randomly or non-randomly. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.rotation.
- Returns
A list of processed images.
- Return type
numpy.array
Examples
>>> x, y --> [row, col, 1] greyscale >>> x, y = tl.prepro.rotation_multi([x, y], rg=90, is_random=False)
Crop¶
-
tensorlayer.prepro.crop(x, wrg, hrg, is_random=False, row_index=0, col_index=1)[source]¶ Randomly or centrally crop an image.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
wrg (int) – Size of width.
hrg (int) – Size of height.
is_random (boolean,) – If True, randomly crop, else central crop. Default is False.
row_index (int) – index of row.
col_index (int) – index of column.
- Returns
A processed image.
- Return type
numpy.array
-
tensorlayer.prepro.crop_multi(x, wrg, hrg, is_random=False, row_index=0, col_index=1)[source]¶ Randomly or centrally crop multiple images.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.crop.
- Returns
A list of processed images.
- Return type
numpy.array
Flip¶
-
tensorlayer.prepro.flip_axis(x, axis=1, is_random=False)[source]¶ Flip the axis of an image, such as flip left and right, up and down, randomly or non-randomly,
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
axis (int) –
- Which axis to flip.
0, flip up and down
1, flip left and right
2, flip channel
is_random (boolean) – If True, randomly flip. Default is False.
- Returns
A processed image.
- Return type
numpy.array
-
tensorlayer.prepro.flip_axis_multi(x, axis, is_random=False)[source]¶ Flip the axises of multiple images together, such as flip left and right, up and down, randomly or non-randomly,
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.flip_axis.
- Returns
A list of processed images.
- Return type
numpy.array
Shift¶
-
tensorlayer.prepro.shift(x, wrg=0.1, hrg=0.1, is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Shift an image randomly or non-randomly.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
wrg (float) – Percentage of shift in axis x, usually -0.25 ~ 0.25.
hrg (float) – Percentage of shift in axis y, usually -0.25 ~ 0.25.
is_random (boolean) – If True, randomly shift. Default is False.
col_index and channel_index (row_index) – Index of row, col and channel, default (0, 1, 2), for theano (1, 2, 0).
fill_mode (str) – Method to fill missing pixel, default nearest, more options constant, reflect or wrap, see scipy ndimage affine_transform
cval (float) – Value used for points outside the boundaries of the input if mode=’constant’. Default is 0.0.
order (int) – The order of interpolation. The order has to be in the range 0-5. See
tl.prepro.affine_transformand scipy ndimage affine_transform
- Returns
A processed image.
- Return type
numpy.array
-
tensorlayer.prepro.shift_multi(x, wrg=0.1, hrg=0.1, is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Shift images with the same arguments, randomly or non-randomly. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.shift.
- Returns
A list of processed images.
- Return type
numpy.array
Shear¶
-
tensorlayer.prepro.shear(x, intensity=0.1, is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Shear an image randomly or non-randomly.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
intensity (float) – Percentage of shear, usually -0.5 ~ 0.5 (is_random==True), 0 ~ 0.5 (is_random==False), you can have a quick try by shear(X, 1).
is_random (boolean) – If True, randomly shear. Default is False.
col_index and channel_index (row_index) – Index of row, col and channel, default (0, 1, 2), for theano (1, 2, 0).
fill_mode (str) – Method to fill missing pixel, default nearest, more options constant, reflect or wrap, see and scipy ndimage affine_transform
cval (float) – Value used for points outside the boundaries of the input if mode=’constant’. Default is 0.0.
order (int) – The order of interpolation. The order has to be in the range 0-5. See
tl.prepro.affine_transformand scipy ndimage affine_transform
- Returns
A processed image.
- Return type
numpy.array
References
-
tensorlayer.prepro.shear_multi(x, intensity=0.1, is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Shear images with the same arguments, randomly or non-randomly. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.shear.
- Returns
A list of processed images.
- Return type
numpy.array
Shear V2¶
-
tensorlayer.prepro.shear2(x, shear=(0.1, 0.1), is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Shear an image randomly or non-randomly.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
shear (tuple of two floats) – Percentage of shear for height and width direction (0, 1).
is_random (boolean) – If True, randomly shear. Default is False.
col_index and channel_index (row_index) – Index of row, col and channel, default (0, 1, 2), for theano (1, 2, 0).
fill_mode (str) – Method to fill missing pixel, default nearest, more options constant, reflect or wrap, see scipy ndimage affine_transform
cval (float) – Value used for points outside the boundaries of the input if mode=’constant’. Default is 0.0.
order (int) – The order of interpolation. The order has to be in the range 0-5. See
tl.prepro.affine_transformand scipy ndimage affine_transform
- Returns
A processed image.
- Return type
numpy.array
References
-
tensorlayer.prepro.shear_multi2(x, shear=(0.1, 0.1), is_random=False, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1)[source]¶ Shear images with the same arguments, randomly or non-randomly. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.shear2.
- Returns
A list of processed images.
- Return type
numpy.array
Swirl¶
-
tensorlayer.prepro.swirl(x, center=None, strength=1, radius=100, rotation=0, output_shape=None, order=1, mode='constant', cval=0, clip=True, preserve_range=False, is_random=False)[source]¶ Swirl an image randomly or non-randomly, see scikit-image swirl API and example.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
center (tuple or 2 int or None) – Center coordinate of transformation (optional).
strength (float) – The amount of swirling applied.
radius (float) – The extent of the swirl in pixels. The effect dies out rapidly beyond radius.
rotation (float) – Additional rotation applied to the image, usually [0, 360], relates to center.
output_shape (tuple of 2 int or None) – Shape of the output image generated (height, width). By default the shape of the input image is preserved.
order (int, optional) – The order of the spline interpolation, default is 1. The order has to be in the range 0-5. See skimage.transform.warp for detail.
mode (str) – One of constant (default), edge, symmetric reflect and wrap. Points outside the boundaries of the input are filled according to the given mode, with constant used as the default. Modes match the behaviour of numpy.pad.
cval (float) – Used in conjunction with mode constant, the value outside the image boundaries.
clip (boolean) – Whether to clip the output to the range of values of the input image. This is enabled by default, since higher order interpolation may produce values outside the given input range.
preserve_range (boolean) – Whether to keep the original range of values. Otherwise, the input image is converted according to the conventions of img_as_float.
is_random (boolean,) –
- If True, random swirl. Default is False.
random center = [(0 ~ x.shape[0]), (0 ~ x.shape[1])]
random strength = [0, strength]
random radius = [1e-10, radius]
random rotation = [-rotation, rotation]
- Returns
A processed image.
- Return type
numpy.array
Examples
>>> x --> [row, col, 1] greyscale >>> x = tl.prepro.swirl(x, strength=4, radius=100)
-
tensorlayer.prepro.swirl_multi(x, center=None, strength=1, radius=100, rotation=0, output_shape=None, order=1, mode='constant', cval=0, clip=True, preserve_range=False, is_random=False)[source]¶ Swirl multiple images with the same arguments, randomly or non-randomly. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.swirl.
- Returns
A list of processed images.
- Return type
numpy.array
Elastic transform¶
-
tensorlayer.prepro.elastic_transform(x, alpha, sigma, mode='constant', cval=0, is_random=False)[source]¶ Elastic transformation for image as described in [Simard2003].
- Parameters
x (numpy.array) – A greyscale image.
alpha (float) – Alpha value for elastic transformation.
sigma (float or sequence of float) – The smaller the sigma, the more transformation. Standard deviation for Gaussian kernel. The standard deviations of the Gaussian filter are given for each axis as a sequence, or as a single number, in which case it is equal for all axes.
mode (str) – See scipy.ndimage.filters.gaussian_filter. Default is constant.
cval (float,) – Used in conjunction with mode of constant, the value outside the image boundaries.
is_random (boolean) – Default is False.
- Returns
A processed image.
- Return type
numpy.array
Examples
>>> x = tl.prepro.elastic_transform(x, alpha=x.shape[1]*3, sigma=x.shape[1]*0.07)
References
-
tensorlayer.prepro.elastic_transform_multi(x, alpha, sigma, mode='constant', cval=0, is_random=False)[source]¶ Elastic transformation for images as described in [Simard2003].
- Parameters
x (list of numpy.array) – List of greyscale images.
others (args) – See
tl.prepro.elastic_transform.
- Returns
A list of processed images.
- Return type
numpy.array
Zoom¶
-
tensorlayer.prepro.zoom(x, zoom_range=(0.9, 1.1), flags=None, border_mode='constant')[source]¶ Zooming/Scaling a single image that height and width are changed together.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
zoom_range (float or tuple of 2 floats) –
- The zooming/scaling ratio, greater than 1 means larger.
float, a fixed ratio.
tuple of 2 floats, randomly sample a value as the ratio between 2 values.
border_mode (str) –
constant, pad the image with a constant value (i.e. black or 0)
replicate, the row or column at the very edge of the original is replicated to the extra border.
- Returns
A processed image.
- Return type
numpy.array
-
tensorlayer.prepro.zoom_multi(x, zoom_range=(0.9, 1.1), flags=None, border_mode='constant')[source]¶ Zoom in and out of images with the same arguments, randomly or non-randomly. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.zoom.
- Returns
A list of processed images.
- Return type
numpy.array
Respective Zoom¶
-
tensorlayer.prepro.respective_zoom(x, h_range=(0.9, 1.1), w_range=(0.9, 1.1), flags=None, border_mode='constant')[source]¶ Zooming/Scaling a single image that height and width are changed independently.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
h_range (float or tuple of 2 floats) –
- The zooming/scaling ratio of height, greater than 1 means larger.
float, a fixed ratio.
tuple of 2 floats, randomly sample a value as the ratio between 2 values.
w_range (float or tuple of 2 floats) –
- The zooming/scaling ratio of width, greater than 1 means larger.
float, a fixed ratio.
tuple of 2 floats, randomly sample a value as the ratio between 2 values.
border_mode (str) –
constant, pad the image with a constant value (i.e. black or 0)
replicate, the row or column at the very edge of the original is replicated to the extra border.
- Returns
A processed image.
- Return type
numpy.array
Brightness¶
-
tensorlayer.prepro.brightness(x, gamma=1, gain=1, is_random=False)[source]¶ Change the brightness of a single image, randomly or non-randomly.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
gamma (float) –
- Non negative real number. Default value is 1.
Small than 1 means brighter.
If is_random is True, gamma in a range of (1-gamma, 1+gamma).
gain (float) – The constant multiplier. Default value is 1.
is_random (boolean) – If True, randomly change brightness. Default is False.
- Returns
A processed image.
- Return type
numpy.array
References
-
tensorlayer.prepro.brightness_multi(x, gamma=1, gain=1, is_random=False)[source]¶ Change the brightness of multiply images, randomly or non-randomly. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpyarray) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.brightness.
- Returns
A list of processed images.
- Return type
numpy.array
Brightness, contrast and saturation¶
-
tensorlayer.prepro.illumination(x, gamma=1.0, contrast=1.0, saturation=1.0, is_random=False)[source]¶ Perform illumination augmentation for a single image, randomly or non-randomly.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
gamma (float) –
- Change brightness (the same with
tl.prepro.brightness) if is_random=False, one float number, small than one means brighter, greater than one means darker.
if is_random=True, tuple of two float numbers, (min, max).
- Change brightness (the same with
contrast (float) –
- Change contrast.
if is_random=False, one float number, small than one means blur.
if is_random=True, tuple of two float numbers, (min, max).
saturation (float) –
- Change saturation.
if is_random=False, one float number, small than one means unsaturation.
if is_random=True, tuple of two float numbers, (min, max).
is_random (boolean) – If True, randomly change illumination. Default is False.
- Returns
A processed image.
- Return type
numpy.array
Examples
Random
>>> x = tl.prepro.illumination(x, gamma=(0.5, 5.0), contrast=(0.3, 1.0), saturation=(0.7, 1.0), is_random=True)
Non-random
>>> x = tl.prepro.illumination(x, 0.5, 0.6, 0.8, is_random=False)
RGB to HSV¶
HSV to RGB¶
Adjust Hue¶
-
tensorlayer.prepro.adjust_hue(im, hout=0.66, is_offset=True, is_clip=True, is_random=False)[source]¶ Adjust hue of an RGB image.
This is a convenience method that converts an RGB image to float representation, converts it to HSV, add an offset to the hue channel, converts back to RGB and then back to the original data type. For TF, see tf.image.adjust_hue.and tf.image.random_hue.
- Parameters
im (numpy.array) – An image with values between 0 and 255.
hout (float) –
- The scale value for adjusting hue.
If is_offset is False, set all hue values to this value. 0 is red; 0.33 is green; 0.66 is blue.
If is_offset is True, add this value as the offset to the hue channel.
is_offset (boolean) – Whether hout is added on HSV as offset or not. Default is True.
is_clip (boolean) – If HSV value smaller than 0, set to 0. Default is True.
is_random (boolean) – If True, randomly change hue. Default is False.
- Returns
A processed image.
- Return type
numpy.array
Examples
Random, add a random value between -0.2 and 0.2 as the offset to every hue values.
>>> im_hue = tl.prepro.adjust_hue(image, hout=0.2, is_offset=True, is_random=False)
Non-random, make all hue to green.
>>> im_green = tl.prepro.adjust_hue(image, hout=0.66, is_offset=False, is_random=False)
References
Resize¶
-
tensorlayer.prepro.imresize(x, size=None, interp='bicubic', mode=None)[source]¶ Resize an image by given output size and method.
Warning, this function will rescale the value to [0, 255].
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
size (list of 2 int or None) – For height and width.
interp (str) – Interpolation method for re-sizing (nearest, lanczos, bilinear, bicubic (default) or cubic).
mode (str) – The PIL image mode (P, L, etc.) to convert image before resizing.
- Returns
A processed image.
- Return type
numpy.array
References
Pixel value scale¶
-
tensorlayer.prepro.pixel_value_scale(im, val=0.9, clip=None, is_random=False)[source]¶ Scales each value in the pixels of the image.
- Parameters
im (numpy.array) – An image.
val (float) –
- The scale value for changing pixel value.
If is_random=False, multiply this value with all pixels.
If is_random=True, multiply a value between [1-val, 1+val] with all pixels.
clip (tuple of 2 numbers) – The minimum and maximum value.
is_random (boolean) – If True, see
val.
- Returns
A processed image.
- Return type
numpy.array
Examples
Random
>>> im = pixel_value_scale(im, 0.1, [0, 255], is_random=True)
Non-random
>>> im = pixel_value_scale(im, 0.9, [0, 255], is_random=False)
Normalization¶
-
tensorlayer.prepro.samplewise_norm(x, rescale=None, samplewise_center=False, samplewise_std_normalization=False, channel_index=2, epsilon=1e-07)[source]¶ Normalize an image by rescale, samplewise centering and samplewise centering in order.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
rescale (float) – Rescaling factor. If None or 0, no rescaling is applied, otherwise we multiply the data by the value provided (before applying any other transformation)
samplewise_center (boolean) – If True, set each sample mean to 0.
samplewise_std_normalization (boolean) – If True, divide each input by its std.
epsilon (float) – A small position value for dividing standard deviation.
- Returns
A processed image.
- Return type
numpy.array
Examples
>>> x = samplewise_norm(x, samplewise_center=True, samplewise_std_normalization=True) >>> print(x.shape, np.mean(x), np.std(x)) (160, 176, 1), 0.0, 1.0
Notes
When samplewise_center and samplewise_std_normalization are True. - For greyscale image, every pixels are subtracted and divided by the mean and std of whole image. - For RGB image, every pixels are subtracted and divided by the mean and std of this pixel i.e. the mean and std of a pixel is 0 and 1.
-
tensorlayer.prepro.featurewise_norm(x, mean=None, std=None, epsilon=1e-07)[source]¶ Normalize every pixels by the same given mean and std, which are usually compute from all examples.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
mean (float) – Value for subtraction.
std (float) – Value for division.
epsilon (float) – A small position value for dividing standard deviation.
- Returns
A processed image.
- Return type
numpy.array
Channel shift¶
-
tensorlayer.prepro.channel_shift(x, intensity, is_random=False, channel_index=2)[source]¶ Shift the channels of an image, randomly or non-randomly, see numpy.rollaxis.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] (default).
intensity (float) – Intensity of shifting.
is_random (boolean) – If True, randomly shift. Default is False.
channel_index (int) – Index of channel. Default is 2.
- Returns
A processed image.
- Return type
numpy.array
-
tensorlayer.prepro.channel_shift_multi(x, intensity, is_random=False, channel_index=2)[source]¶ Shift the channels of images with the same arguments, randomly or non-randomly, see numpy.rollaxis. Usually be used for image segmentation which x=[X, Y], X and Y should be matched.
- Parameters
x (list of numpy.array) – List of images with dimension of [n_images, row, col, channel] (default).
others (args) – See
tl.prepro.channel_shift.
- Returns
A list of processed images.
- Return type
numpy.array
Noise¶
-
tensorlayer.prepro.drop(x, keep=0.5)[source]¶ Randomly set some pixels to zero by a given keeping probability.
- Parameters
x (numpy.array) – An image with dimension of [row, col, channel] or [row, col].
keep (float) – The keeping probability (0, 1), the lower more values will be set to zero.
- Returns
A processed image.
- Return type
numpy.array
Numpy and PIL¶
-
tensorlayer.prepro.array_to_img(x, dim_ordering=(0, 1, 2), scale=True)[source]¶ Converts a numpy array to PIL image object (uint8 format).
- Parameters
x (numpy.array) – An image with dimension of 3 and channels of 1 or 3.
dim_ordering (tuple of 3 int) – Index of row, col and channel, default (0, 1, 2), for theano (1, 2, 0).
scale (boolean) – If True, converts image to [0, 255] from any range of value like [-1, 2]. Default is True.
- Returns
An image.
- Return type
PIL.image
References
Find contours¶
-
tensorlayer.prepro.find_contours(x, level=0.8, fully_connected='low', positive_orientation='low')[source]¶ Find iso-valued contours in a 2D array for a given level value, returns list of (n, 2)-ndarrays see skimage.measure.find_contours.
- Parameters
x (2D ndarray of double.) – Input data in which to find contours.
level (float) – Value along which to find contours in the array.
fully_connected (str) – Either low or high. Indicates whether array elements below the given level value are to be considered fully-connected (and hence elements above the value will only be face connected), or vice-versa. (See notes below for details.)
positive_orientation (str) – Either low or high. Indicates whether the output contours will produce positively-oriented polygons around islands of low- or high-valued elements. If low then contours will wind counter-clockwise around elements below the iso-value. Alternately, this means that low-valued elements are always on the left of the contour.
- Returns
Each contour is an ndarray of shape (n, 2), consisting of n (row, column) coordinates along the contour.
- Return type
list of (n,2)-ndarrays
Points to Image¶
-
tensorlayer.prepro.pt2map(list_points=None, size=(100, 100), val=1)[source]¶ Inputs a list of points, return a 2D image.
- Parameters
list_points (list of 2 int) – [[x, y], [x, y]..] for point coordinates.
size (tuple of 2 int) – (w, h) for output size.
val (float or int) – For the contour value.
- Returns
An image.
- Return type
numpy.array
Binary dilation¶
-
tensorlayer.prepro.binary_dilation(x, radius=3)[source]¶ Return fast binary morphological dilation of an image. see skimage.morphology.binary_dilation.
- Parameters
x (2D array) – A binary image.
radius (int) – For the radius of mask.
- Returns
A processed binary image.
- Return type
numpy.array
Greyscale dilation¶
-
tensorlayer.prepro.dilation(x, radius=3)[source]¶ Return greyscale morphological dilation of an image, see skimage.morphology.dilation.
- Parameters
x (2D array) – An greyscale image.
radius (int) – For the radius of mask.
- Returns
A processed greyscale image.
- Return type
numpy.array
Binary erosion¶
-
tensorlayer.prepro.binary_erosion(x, radius=3)[source]¶ Return binary morphological erosion of an image, see skimage.morphology.binary_erosion.
- Parameters
x (2D array) – A binary image.
radius (int) – For the radius of mask.
- Returns
A processed binary image.
- Return type
numpy.array
Greyscale erosion¶
-
tensorlayer.prepro.erosion(x, radius=3)[source]¶ Return greyscale morphological erosion of an image, see skimage.morphology.erosion.
- Parameters
x (2D array) – A greyscale image.
radius (int) – For the radius of mask.
- Returns
A processed greyscale image.
- Return type
numpy.array
Object detection¶
Tutorial for Image Aug¶
Hi, here is an example for image augmentation on VOC dataset.
import tensorlayer as tl
## download VOC 2012 dataset
imgs_file_list, _, _, _, classes, _, _,\
_, objs_info_list, _ = tl.files.load_voc_dataset(dataset="2012")
## parse annotation and convert it into list format
ann_list = []
for info in objs_info_list:
ann = tl.prepro.parse_darknet_ann_str_to_list(info)
c, b = tl.prepro.parse_darknet_ann_list_to_cls_box(ann)
ann_list.append([c, b])
# read and save one image
idx = 2 # you can select your own image
image = tl.vis.read_image(imgs_file_list[idx])
tl.vis.draw_boxes_and_labels_to_image(image, ann_list[idx][0],
ann_list[idx][1], [], classes, True, save_name='_im_original.png')
# left right flip
im_flip, coords = tl.prepro.obj_box_horizontal_flip(image,
ann_list[idx][1], is_rescale=True, is_center=True, is_random=False)
tl.vis.draw_boxes_and_labels_to_image(im_flip, ann_list[idx][0],
coords, [], classes, True, save_name='_im_flip.png')
# resize
im_resize, coords = tl.prepro.obj_box_imresize(image,
coords=ann_list[idx][1], size=[300, 200], is_rescale=True)
tl.vis.draw_boxes_and_labels_to_image(im_resize, ann_list[idx][0],
coords, [], classes, True, save_name='_im_resize.png')
# crop
im_crop, clas, coords = tl.prepro.obj_box_crop(image, ann_list[idx][0],
ann_list[idx][1], wrg=200, hrg=200,
is_rescale=True, is_center=True, is_random=False)
tl.vis.draw_boxes_and_labels_to_image(im_crop, clas, coords, [],
classes, True, save_name='_im_crop.png')
# shift
im_shfit, clas, coords = tl.prepro.obj_box_shift(image, ann_list[idx][0],
ann_list[idx][1], wrg=0.1, hrg=0.1,
is_rescale=True, is_center=True, is_random=False)
tl.vis.draw_boxes_and_labels_to_image(im_shfit, clas, coords, [],
classes, True, save_name='_im_shift.png')
# zoom
im_zoom, clas, coords = tl.prepro.obj_box_zoom(image, ann_list[idx][0],
ann_list[idx][1], zoom_range=(1.3, 0.7),
is_rescale=True, is_center=True, is_random=False)
tl.vis.draw_boxes_and_labels_to_image(im_zoom, clas, coords, [],
classes, True, save_name='_im_zoom.png')
In practice, you may want to use threading method to process a batch of images as follows.
import tensorlayer as tl
import random
batch_size = 64
im_size = [416, 416]
n_data = len(imgs_file_list)
jitter = 0.2
def _data_pre_aug_fn(data):
im, ann = data
clas, coords = ann
## change image brightness, contrast and saturation randomly
im = tl.prepro.illumination(im, gamma=(0.5, 1.5),
contrast=(0.5, 1.5), saturation=(0.5, 1.5), is_random=True)
## flip randomly
im, coords = tl.prepro.obj_box_horizontal_flip(im, coords,
is_rescale=True, is_center=True, is_random=True)
## randomly resize and crop image, it can have same effect as random zoom
tmp0 = random.randint(1, int(im_size[0]*jitter))
tmp1 = random.randint(1, int(im_size[1]*jitter))
im, coords = tl.prepro.obj_box_imresize(im, coords,
[im_size[0]+tmp0, im_size[1]+tmp1], is_rescale=True,
interp='bicubic')
im, clas, coords = tl.prepro.obj_box_crop(im, clas, coords,
wrg=im_size[1], hrg=im_size[0], is_rescale=True,
is_center=True, is_random=True)
## rescale value from [0, 255] to [-1, 1] (optional)
im = im / 127.5 - 1
return im, [clas, coords]
# randomly read a batch of image and the corresponding annotations
idexs = tl.utils.get_random_int(min=0, max=n_data-1, number=batch_size)
b_im_path = [imgs_file_list[i] for i in idexs]
b_images = tl.prepro.threading_data(b_im_path, fn=tl.vis.read_image)
b_ann = [ann_list[i] for i in idexs]
# threading process
data = tl.prepro.threading_data([_ for _ in zip(b_images, b_ann)],
_data_pre_aug_fn)
b_images2 = [d[0] for d in data]
b_ann = [d[1] for d in data]
# save all images
for i in range(len(b_images)):
tl.vis.draw_boxes_and_labels_to_image(b_images[i],
ann_list[idexs[i]][0], ann_list[idexs[i]][1], [],
classes, True, save_name='_bbox_vis_%d_original.png' % i)
tl.vis.draw_boxes_and_labels_to_image((b_images2[i]+1)*127.5,
b_ann[i][0], b_ann[i][1], [], classes, True,
save_name='_bbox_vis_%d.png' % i)
Coordinate pixel unit to percentage¶
-
tensorlayer.prepro.obj_box_coord_rescale(coord=None, shape=None)[source]¶ Scale down one coordinates from pixel unit to the ratio of image size i.e. in the range of [0, 1]. It is the reverse process of
obj_box_coord_scale_to_pixelunit.- Parameters
coords (list of 4 int or None) – One coordinates of one image e.g. [x, y, w, h].
shape (list of 2 int or None) – For [height, width].
- Returns
New bounding box.
- Return type
list of 4 numbers
Examples
>>> coord = tl.prepro.obj_box_coord_rescale(coord=[30, 40, 50, 50], shape=[100, 100]) [0.3, 0.4, 0.5, 0.5]
Coordinates pixel unit to percentage¶
-
tensorlayer.prepro.obj_box_coords_rescale(coords=None, shape=None)[source]¶ Scale down a list of coordinates from pixel unit to the ratio of image size i.e. in the range of [0, 1].
- Parameters
coords (list of list of 4 ints or None) – For coordinates of more than one images .e.g.[[x, y, w, h], [x, y, w, h], …].
shape (list of 2 int or None) – 【height, width].
- Returns
A list of new bounding boxes.
- Return type
list of list of 4 numbers
Examples
>>> coords = obj_box_coords_rescale(coords=[[30, 40, 50, 50], [10, 10, 20, 20]], shape=[100, 100]) >>> print(coords) [[0.3, 0.4, 0.5, 0.5], [0.1, 0.1, 0.2, 0.2]] >>> coords = obj_box_coords_rescale(coords=[[30, 40, 50, 50]], shape=[50, 100]) >>> print(coords) [[0.3, 0.8, 0.5, 1.0]] >>> coords = obj_box_coords_rescale(coords=[[30, 40, 50, 50]], shape=[100, 200]) >>> print(coords) [[0.15, 0.4, 0.25, 0.5]]
- Returns
New coordinates.
- Return type
list of 4 numbers
Coordinate percentage to pixel unit¶
-
tensorlayer.prepro.obj_box_coord_scale_to_pixelunit(coord, shape=None)[source]¶ Convert one coordinate [x, y, w (or x2), h (or y2)] in ratio format to image coordinate format. It is the reverse process of
obj_box_coord_rescale.- Parameters
coord (list of 4 float) – One coordinate of one image [x, y, w (or x2), h (or y2)] in ratio format, i.e value range [0~1].
shape (tuple of 2 or None) – For [height, width].
- Returns
New bounding box.
- Return type
list of 4 numbers
Examples
>>> x, y, x2, y2 = tl.prepro.obj_box_coord_scale_to_pixelunit([0.2, 0.3, 0.5, 0.7], shape=(100, 200, 3)) [40, 30, 100, 70]
Coordinate [x_center, x_center, w, h] to up-left button-right¶
-
tensorlayer.prepro.obj_box_coord_centroid_to_upleft_butright(coord, to_int=False)[source]¶ Convert one coordinate [x_center, y_center, w, h] to [x1, y1, x2, y2] in up-left and botton-right format.
- Parameters
coord (list of 4 int/float) – One coordinate.
to_int (boolean) – Whether to convert output as integer.
- Returns
New bounding box.
- Return type
list of 4 numbers
Examples
>>> coord = obj_box_coord_centroid_to_upleft_butright([30, 40, 20, 20]) [20, 30, 40, 50]
Coordinate up-left button-right to [x_center, x_center, w, h]¶
-
tensorlayer.prepro.obj_box_coord_upleft_butright_to_centroid(coord)[source]¶ Convert one coordinate [x1, y1, x2, y2] to [x_center, y_center, w, h]. It is the reverse process of
obj_box_coord_centroid_to_upleft_butright.- Parameters
coord (list of 4 int/float) – One coordinate.
- Returns
New bounding box.
- Return type
list of 4 numbers
Coordinate [x_center, x_center, w, h] to up-left-width-high¶
-
tensorlayer.prepro.obj_box_coord_centroid_to_upleft(coord)[source]¶ Convert one coordinate [x_center, y_center, w, h] to [x, y, w, h]. It is the reverse process of
obj_box_coord_upleft_to_centroid.- Parameters
coord (list of 4 int/float) – One coordinate.
- Returns
New bounding box.
- Return type
list of 4 numbers
Coordinate up-left-width-high to [x_center, x_center, w, h]¶
-
tensorlayer.prepro.obj_box_coord_upleft_to_centroid(coord)[source]¶ Convert one coordinate [x, y, w, h] to [x_center, y_center, w, h]. It is the reverse process of
obj_box_coord_centroid_to_upleft.- Parameters
coord (list of 4 int/float) – One coordinate.
- Returns
New bounding box.
- Return type
list of 4 numbers
Darknet format string to list¶
-
tensorlayer.prepro.parse_darknet_ann_str_to_list(annotations)[source]¶ Input string format of class, x, y, w, h, return list of list format.
- Parameters
annotations (str) – The annotations in darkent format “class, x, y, w, h ….” seperated by “\n”.
- Returns
List of bounding box.
- Return type
list of list of 4 numbers
Darknet format split class and coordinate¶
-
tensorlayer.prepro.parse_darknet_ann_list_to_cls_box(annotations)[source]¶ Parse darknet annotation format into two lists for class and bounding box.
Input list of [[class, x, y, w, h], …], return two list of [class …] and [[x, y, w, h], …].
- Parameters
annotations (list of list) – A list of class and bounding boxes of images e.g. [[class, x, y, w, h], …]
- Returns
list of int – List of class labels.
list of list of 4 numbers – List of bounding box.
Image Aug - Flip¶
-
tensorlayer.prepro.obj_box_horizontal_flip(im, coords=None, is_rescale=False, is_center=False, is_random=False)[source]¶ Left-right flip the image and coordinates for object detection.
- Parameters
im (numpy.array) – An image with dimension of [row, col, channel] (default).
coords (list of list of 4 int/float or None) – Coordinates [[x, y, w, h], [x, y, w, h], …].
is_rescale (boolean) – Set to True, if the input coordinates are rescaled to [0, 1]. Default is False.
is_center (boolean) – Set to True, if the x and y of coordinates are the centroid (i.e. darknet format). Default is False.
is_random (boolean) – If True, randomly flip. Default is False.
- Returns
numpy.array – A processed image
list of list of 4 numbers – A list of new bounding boxes.
Examples
>>> im = np.zeros([80, 100]) # as an image with shape width=100, height=80 >>> im, coords = obj_box_left_right_flip(im, coords=[[0.2, 0.4, 0.3, 0.3], [0.1, 0.5, 0.2, 0.3]], is_rescale=True, is_center=True, is_random=False) >>> print(coords) [[0.8, 0.4, 0.3, 0.3], [0.9, 0.5, 0.2, 0.3]] >>> im, coords = obj_box_left_right_flip(im, coords=[[0.2, 0.4, 0.3, 0.3]], is_rescale=True, is_center=False, is_random=False) >>> print(coords) [[0.5, 0.4, 0.3, 0.3]] >>> im, coords = obj_box_left_right_flip(im, coords=[[20, 40, 30, 30]], is_rescale=False, is_center=True, is_random=False) >>> print(coords) [[80, 40, 30, 30]] >>> im, coords = obj_box_left_right_flip(im, coords=[[20, 40, 30, 30]], is_rescale=False, is_center=False, is_random=False) >>> print(coords) [[50, 40, 30, 30]]
Image Aug - Resize¶
-
tensorlayer.prepro.obj_box_imresize(im, coords=None, size=None, interp='bicubic', mode=None, is_rescale=False)[source]¶ Resize an image, and compute the new bounding box coordinates.
- Parameters
im (numpy.array) – An image with dimension of [row, col, channel] (default).
coords (list of list of 4 int/float or None) – Coordinates [[x, y, w, h], [x, y, w, h], …]
interp and mode (size) – See
tl.prepro.imresize.is_rescale (boolean) – Set to True, if the input coordinates are rescaled to [0, 1], then return the original coordinates. Default is False.
- Returns
numpy.array – A processed image
list of list of 4 numbers – A list of new bounding boxes.
Examples
>>> im = np.zeros([80, 100, 3]) # as an image with shape width=100, height=80 >>> _, coords = obj_box_imresize(im, coords=[[20, 40, 30, 30], [10, 20, 20, 20]], size=[160, 200], is_rescale=False) >>> print(coords) [[40, 80, 60, 60], [20, 40, 40, 40]] >>> _, coords = obj_box_imresize(im, coords=[[20, 40, 30, 30]], size=[40, 100], is_rescale=False) >>> print(coords) [[20, 20, 30, 15]] >>> _, coords = obj_box_imresize(im, coords=[[20, 40, 30, 30]], size=[60, 150], is_rescale=False) >>> print(coords) [[30, 30, 45, 22]] >>> im2, coords = obj_box_imresize(im, coords=[[0.2, 0.4, 0.3, 0.3]], size=[160, 200], is_rescale=True) >>> print(coords, im2.shape) [[0.2, 0.4, 0.3, 0.3]] (160, 200, 3)
Image Aug - Crop¶
-
tensorlayer.prepro.obj_box_crop(im, classes=None, coords=None, wrg=100, hrg=100, is_rescale=False, is_center=False, is_random=False, thresh_wh=0.02, thresh_wh2=12.0)[source]¶ Randomly or centrally crop an image, and compute the new bounding box coordinates. Objects outside the cropped image will be removed.
- Parameters
im (numpy.array) – An image with dimension of [row, col, channel] (default).
classes (list of int or None) – Class IDs.
coords (list of list of 4 int/float or None) – Coordinates [[x, y, w, h], [x, y, w, h], …]
hrg and is_random (wrg) – See
tl.prepro.crop.is_rescale (boolean) – Set to True, if the input coordinates are rescaled to [0, 1]. Default is False.
is_center (boolean, default False) – Set to True, if the x and y of coordinates are the centroid (i.e. darknet format). Default is False.
thresh_wh (float) – Threshold, remove the box if its ratio of width(height) to image size less than the threshold.
thresh_wh2 (float) – Threshold, remove the box if its ratio of width to height or vice verse higher than the threshold.
- Returns
numpy.array – A processed image
list of int – A list of classes
list of list of 4 numbers – A list of new bounding boxes.
Image Aug - Shift¶
-
tensorlayer.prepro.obj_box_shift(im, classes=None, coords=None, wrg=0.1, hrg=0.1, row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1, is_rescale=False, is_center=False, is_random=False, thresh_wh=0.02, thresh_wh2=12.0)[source]¶ Shift an image randomly or non-randomly, and compute the new bounding box coordinates. Objects outside the cropped image will be removed.
- Parameters
im (numpy.array) – An image with dimension of [row, col, channel] (default).
classes (list of int or None) – Class IDs.
coords (list of list of 4 int/float or None) – Coordinates [[x, y, w, h], [x, y, w, h], …]
hrg row_index col_index channel_index is_random fill_mode cval and order (wrg,) –
is_rescale (boolean) – Set to True, if the input coordinates are rescaled to [0, 1]. Default is False.
is_center (boolean) – Set to True, if the x and y of coordinates are the centroid (i.e. darknet format). Default is False.
thresh_wh (float) – Threshold, remove the box if its ratio of width(height) to image size less than the threshold.
thresh_wh2 (float) – Threshold, remove the box if its ratio of width to height or vice verse higher than the threshold.
- Returns
numpy.array – A processed image
list of int – A list of classes
list of list of 4 numbers – A list of new bounding boxes.
Image Aug - Zoom¶
-
tensorlayer.prepro.obj_box_zoom(im, classes=None, coords=None, zoom_range=(0.9, 1.1), row_index=0, col_index=1, channel_index=2, fill_mode='nearest', cval=0.0, order=1, is_rescale=False, is_center=False, is_random=False, thresh_wh=0.02, thresh_wh2=12.0)[source]¶ Zoom in and out of a single image, randomly or non-randomly, and compute the new bounding box coordinates. Objects outside the cropped image will be removed.
- Parameters
im (numpy.array) – An image with dimension of [row, col, channel] (default).
classes (list of int or None) – Class IDs.
coords (list of list of 4 int/float or None) – Coordinates [[x, y, w, h], [x, y, w, h], …].
row_index col_index channel_index is_random fill_mode cval and order (zoom_range) –
is_rescale (boolean) – Set to True, if the input coordinates are rescaled to [0, 1]. Default is False.
is_center (boolean) – Set to True, if the x and y of coordinates are the centroid. (i.e. darknet format). Default is False.
thresh_wh (float) – Threshold, remove the box if its ratio of width(height) to image size less than the threshold.
thresh_wh2 (float) – Threshold, remove the box if its ratio of width to height or vice verse higher than the threshold.
- Returns
numpy.array – A processed image
list of int – A list of classes
list of list of 4 numbers – A list of new bounding boxes.
Keypoints¶
Image Aug - Crop¶
-
tensorlayer.prepro.keypoint_random_crop(image, annos, mask=None, size=(368, 368))[source]¶ Randomly crop an image and corresponding keypoints without influence scales, given by
keypoint_random_resize_shortestedge.- Parameters
image (3 channel image) – The given image for augmentation.
annos (list of list of floats) – The keypoints annotation of people.
mask (single channel image or None) – The mask if available.
size (tuple of int) – The size of returned image.
- Returns
- Return type
preprocessed image, annotation, mask
Image Aug - Resize then Crop¶
-
tensorlayer.prepro.keypoint_resize_random_crop(image, annos, mask=None, size=(368, 368))[source]¶ Reszie the image to make either its width or height equals to the given sizes. Then randomly crop image without influence scales. Resize the image match with the minimum size before cropping, this API will change the zoom scale of object.
- Parameters
image (3 channel image) – The given image for augmentation.
annos (list of list of floats) – The keypoints annotation of people.
mask (single channel image or None) – The mask if available.
size (tuple of int) – The size (height, width) of returned image.
- Returns
- Return type
preprocessed image, annos, mask
Image Aug - Rotate¶
-
tensorlayer.prepro.keypoint_random_rotate(image, annos, mask=None, rg=15.0)[source]¶ Rotate an image and corresponding keypoints.
- Parameters
image (3 channel image) – The given image for augmentation.
annos (list of list of floats) – The keypoints annotation of people.
mask (single channel image or None) – The mask if available.
rg (int or float) – Degree to rotate, usually 0 ~ 180.
- Returns
- Return type
preprocessed image, annos, mask
Image Aug - Flip¶
-
tensorlayer.prepro.keypoint_random_flip(image, annos, mask=None, prob=0.5, flip_list=(0, 1, 5, 6, 7, 2, 3, 4, 11, 12, 13, 8, 9, 10, 15, 14, 17, 16, 18))[source]¶ Flip an image and corresponding keypoints.
- Parameters
image (3 channel image) – The given image for augmentation.
annos (list of list of floats) – The keypoints annotation of people.
mask (single channel image or None) – The mask if available.
prob (float, 0 to 1) – The probability to flip the image, if 1, always flip the image.
flip_list (tuple of int) – Denotes how the keypoints number be changed after flipping which is required for pose estimation task. The left and right body should be maintained rather than switch. (Default COCO format). Set to an empty tuple if you don’t need to maintain left and right information.
- Returns
- Return type
preprocessed image, annos, mask
Image Aug - Resize¶
-
tensorlayer.prepro.keypoint_random_resize(image, annos, mask=None, zoom_range=(0.8, 1.2))[source]¶ Randomly resize an image and corresponding keypoints. The height and width of image will be changed independently, so the scale will be changed.
- Parameters
image (3 channel image) – The given image for augmentation.
annos (list of list of floats) – The keypoints annotation of people.
mask (single channel image or None) – The mask if available.
zoom_range (tuple of two floats) – The minimum and maximum factor to zoom in or out, e.g (0.5, 1) means zoom out 1~2 times.
- Returns
- Return type
preprocessed image, annos, mask
Image Aug - Resize Shortest Edge¶
-
tensorlayer.prepro.keypoint_random_resize_shortestedge(image, annos, mask=None, min_size=(368, 368), zoom_range=(0.8, 1.2), pad_val=(0, 0, numpy.random.uniform))[source]¶ Randomly resize an image and corresponding keypoints based on shorter edgeself. If the resized image is smaller than min_size, uses padding to make shape matchs min_size. The height and width of image will be changed together, the scale would not be changed.
- Parameters
image (3 channel image) – The given image for augmentation.
annos (list of list of floats) – The keypoints annotation of people.
mask (single channel image or None) – The mask if available.
min_size (tuple of two int) – The minimum size of height and width.
zoom_range (tuple of two floats) – The minimum and maximum factor to zoom in or out, e.g (0.5, 1) means zoom out 1~2 times.
pad_val (int/float, or tuple of int or random function) – The three padding values for RGB channels respectively.
- Returns
- Return type
preprocessed image, annos, mask
Sequence¶
More related functions can be found in tensorlayer.nlp.
Padding¶
-
tensorlayer.prepro.pad_sequences(sequences, maxlen=None, dtype='int32', padding='post', truncating='pre', value=0.0)[source]¶ Pads each sequence to the same length: the length of the longest sequence. If maxlen is provided, any sequence longer than maxlen is truncated to maxlen. Truncation happens off either the beginning (default) or the end of the sequence. Supports post-padding and pre-padding (default).
- Parameters
sequences (list of list of int) – All sequences where each row is a sequence.
maxlen (int) – Maximum length.
dtype (numpy.dtype or str) – Data type to cast the resulting sequence.
padding (str) – Either ‘pre’ or ‘post’, pad either before or after each sequence.
truncating (str) – Either ‘pre’ or ‘post’, remove values from sequences larger than maxlen either in the beginning or in the end of the sequence
value (float) – Value to pad the sequences to the desired value.
- Returns
x – With dimensions (number_of_sequences, maxlen)
- Return type
numpy.array
Examples
>>> sequences = [[1,1,1,1,1],[2,2,2],[3,3]] >>> sequences = pad_sequences(sequences, maxlen=None, dtype='int32', ... padding='post', truncating='pre', value=0.) [[1 1 1 1 1] [2 2 2 0 0] [3 3 0 0 0]]
Remove Padding¶
-
tensorlayer.prepro.remove_pad_sequences(sequences, pad_id=0)[source]¶ Remove padding.
- Parameters
sequences (list of list of int) – All sequences where each row is a sequence.
pad_id (int) – The pad ID.
- Returns
The processed sequences.
- Return type
list of list of int
Examples
>>> sequences = [[2,3,4,0,0], [5,1,2,3,4,0,0,0], [4,5,0,2,4,0,0,0]] >>> print(remove_pad_sequences(sequences, pad_id=0)) [[2, 3, 4], [5, 1, 2, 3, 4], [4, 5, 0, 2, 4]]
Process¶
-
tensorlayer.prepro.process_sequences(sequences, end_id=0, pad_val=0, is_shorten=True, remain_end_id=False)[source]¶ Set all tokens(ids) after END token to the padding value, and then shorten (option) it to the maximum sequence length in this batch.
- Parameters
sequences (list of list of int) – All sequences where each row is a sequence.
end_id (int) – The special token for END.
pad_val (int) – Replace the end_id and the IDs after end_id to this value.
is_shorten (boolean) – Shorten the sequences. Default is True.
remain_end_id (boolean) – Keep an end_id in the end. Default is False.
- Returns
The processed sequences.
- Return type
list of list of int
Examples
>>> sentences_ids = [[4, 3, 5, 3, 2, 2, 2, 2], <-- end_id is 2 ... [5, 3, 9, 4, 9, 2, 2, 3]] <-- end_id is 2 >>> sentences_ids = precess_sequences(sentences_ids, end_id=vocab.end_id, pad_val=0, is_shorten=True) [[4, 3, 5, 3, 0], [5, 3, 9, 4, 9]]
Add Start ID¶
-
tensorlayer.prepro.sequences_add_start_id(sequences, start_id=0, remove_last=False)[source]¶ Add special start token(id) in the beginning of each sequence.
- Parameters
sequences (list of list of int) – All sequences where each row is a sequence.
start_id (int) – The start ID.
remove_last (boolean) – Remove the last value of each sequences. Usually be used for removing the end ID.
- Returns
The processed sequences.
- Return type
list of list of int
Examples
>>> sentences_ids = [[4,3,5,3,2,2,2,2], [5,3,9,4,9,2,2,3]] >>> sentences_ids = sequences_add_start_id(sentences_ids, start_id=2) [[2, 4, 3, 5, 3, 2, 2, 2, 2], [2, 5, 3, 9, 4, 9, 2, 2, 3]] >>> sentences_ids = sequences_add_start_id(sentences_ids, start_id=2, remove_last=True) [[2, 4, 3, 5, 3, 2, 2, 2], [2, 5, 3, 9, 4, 9, 2, 2]]
For Seq2seq
>>> input = [a, b, c] >>> target = [x, y, z] >>> decode_seq = [start_id, a, b] <-- sequences_add_start_id(input, start_id, True)
Add End ID¶
-
tensorlayer.prepro.sequences_add_end_id(sequences, end_id=888)[source]¶ Add special end token(id) in the end of each sequence.
- Parameters
sequences (list of list of int) – All sequences where each row is a sequence.
end_id (int) – The end ID.
- Returns
The processed sequences.
- Return type
list of list of int
Examples
>>> sequences = [[1,2,3],[4,5,6,7]] >>> print(sequences_add_end_id(sequences, end_id=999)) [[1, 2, 3, 999], [4, 5, 6, 999]]
Add End ID after pad¶
-
tensorlayer.prepro.sequences_add_end_id_after_pad(sequences, end_id=888, pad_id=0)[source]¶ Add special end token(id) in the end of each sequence.
- Parameters
sequences (list of list of int) – All sequences where each row is a sequence.
end_id (int) – The end ID.
pad_id (int) – The pad ID.
- Returns
The processed sequences.
- Return type
list of list of int
Examples
>>> sequences = [[1,2,0,0], [1,2,3,0], [1,2,3,4]] >>> print(sequences_add_end_id_after_pad(sequences, end_id=99, pad_id=0)) [[1, 2, 99, 0], [1, 2, 3, 99], [1, 2, 3, 4]]
Get Mask¶
-
tensorlayer.prepro.sequences_get_mask(sequences, pad_val=0)[source]¶ Return mask for sequences.
- Parameters
sequences (list of list of int) – All sequences where each row is a sequence.
pad_val (int) – The pad value.
- Returns
The mask.
- Return type
list of list of int
Examples
>>> sentences_ids = [[4, 0, 5, 3, 0, 0], ... [5, 3, 9, 4, 9, 0]] >>> mask = sequences_get_mask(sentences_ids, pad_val=0) [[1 1 1 1 0 0] [1 1 1 1 1 0]]